Unified Tasks
One framework supports child synthesis from father-mother pairs and partner synthesis from a child and one parent.
A unified kinship face synthesis framework for generating diverse, high-fidelity child and partner faces with controllable age, gender, and relational resemblance.
Research Center for Information Technology Innovation, Academia Sinica
* Equal contribution
Abstract
StyleDiT combines a diffusion transformer with StyleGAN's style latent space to sample kinship-aware face latents from two conditioning images. The framework handles both child prediction from parents and partner prediction from a child-parent pair, while preserving fine-grained controls over age and gender. Relational Trait Guidance gives independent control over each conditioning face, improving the balance between diversity and fidelity.
One framework supports child synthesis from father-mother pairs and partner synthesis from a child and one parent.
Sampling in StyleGAN S-space with a diffusion prior produces multiple plausible outcomes from the same kinship conditions.
Age, gender, and parent-specific resemblance can be adjusted while keeping high visual fidelity from the StyleGAN generator.
Interactive Browser
The interface is ready for the offline generated assets: two fathers, two mothers, gender tabs, an age slider, and four stochastic child predictions for each condition.
Partner Synthesis
Figure 7 demonstrates the second task in StyleDiT: given a child and one known parent, the same framework synthesizes diverse candidate partners while preserving plausible family traits.

Method
Input faces are encoded into StyleGAN style latents. StyleDiT denoises a sampled latent conditioned on both inputs, then StyleGAN2 decodes the result. Relational Trait Guidance extends classifier-free guidance to independently tune the influence of each condition.
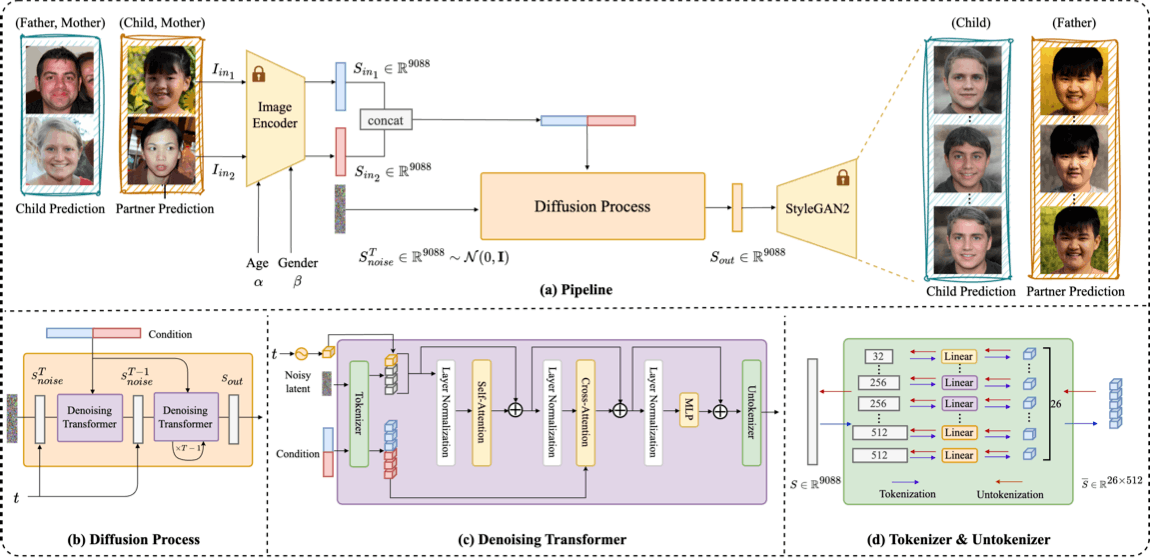
Results
We highlight the experiments most tied to StyleDiT's contributions: Relational Trait Guidance, qualitative child synthesis against prior baselines, and the limitation of relying on scarce real kinship data.
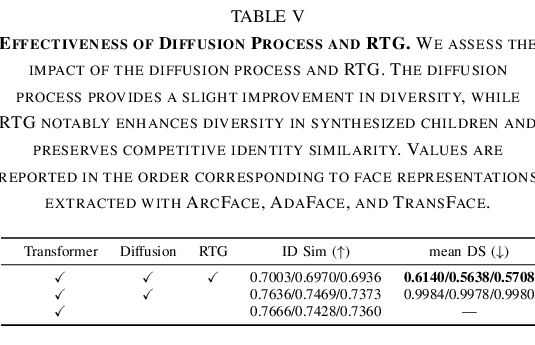
Relational Trait Guidance
Varying father and mother guidance scales shifts the generated child toward the selected condition. The ablation also shows that RTG notably improves diversity while preserving competitive identity similarity.


Child Prediction
Compared with StyleGene, ChildNet, KinStyle, ChildPredictor, and FreeMorph, StyleDiT better balances diversity, visual quality, parental traits, and explicit age/gender control.

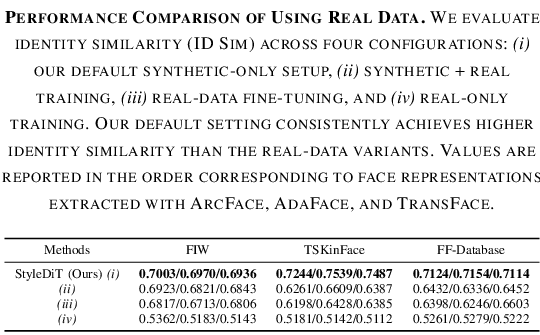
Real Data Ablation
Training with synthetic plus real data, fine-tuning on real data, or using real data only did not improve overall identity similarity. This supports the paper's observation that current real kinship datasets remain limited in quantity and quality.

Citation
Accepted to the 2026 IEEE International Conference on Automatic Face and Gesture Recognition as an oral presentation.
@inproceedings{chiu2026styledit,
title={StyleDiT: A Unified Framework for Diverse Child and Partner Faces Synthesis with Style Latent Diffusion Transformer},
author={Chiu, Pin-Yen and Wu, Dai-Jie and Chu, Po-Hsun and Hsu, Chia-Hsuan and Chiu, Hsiang-Chen and Wang, Chih-Yu and Chen, Jun-Cheng},
booktitle={2026 IEEE International Conference on Automatic Face and Gesture Recognition (FG)},
year={2026}
}